
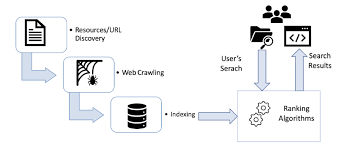
The Importance of Crawling in SEO
When it comes to Search Engine Optimization (SEO), one of the fundamental processes that plays a crucial role in determining a website’s visibility and ranking on search engine results pages is crawling. In simple terms, crawling is the process by which search engines discover and index web pages across the internet.
Search engine crawlers, also known as bots or spiders, scan websites by following links from one page to another. This process enables search engines to gather information about the content, structure, and relevance of each web page. By crawling a website, search engines can determine its quality, relevance, and authority, which are key factors in ranking websites in search results.
For website owners and SEO professionals, understanding how crawling works is essential for ensuring that their web pages are effectively indexed and ranked by search engines. By optimizing a website’s structure, internal linking, and XML sitemap, they can facilitate the crawling process and improve their site’s visibility in search results.
Regularly monitoring crawl errors, fixing broken links, and updating XML sitemaps can help ensure that search engine crawlers can access and index all relevant pages on a website. Additionally, providing clear navigation paths and optimizing meta tags can further enhance a site’s crawlability and indexing efficiency.
Furthermore, implementing best practices such as using robots.txt files to control crawler access and setting up canonical tags to avoid duplicate content issues can help streamline the crawling process and prevent potential indexing errors.
In conclusion, crawling is a fundamental aspect of SEO that directly impacts a website’s visibility and ranking on search engine results pages. By understanding how crawling works and implementing effective strategies to optimize crawlability, website owners can improve their chances of achieving higher rankings and driving organic traffic to their sites.
Mastering the Basics of SEO: A Guide to Understanding Crawling, Its Importance, and Optimisation Techniques
- What is crawling in SEO?
- How do search engine crawlers work?
- Why is crawling important for SEO?
- What are some common issues related to crawling in SEO?
- How can I improve the crawlability of my website?
- What is the difference between crawling and indexing?
- Are there any tools available to help monitor website crawling activity?
- What are some best practices for optimising a website’s crawl budget?
What is crawling in SEO?
Crawling in SEO refers to the process by which search engine bots systematically navigate through websites, analyzing and indexing their content. This essential function allows search engines to discover and understand the information presented on web pages, ultimately influencing a site’s visibility and ranking in search results. By following links and scanning content, crawlers gather data that informs search engines about the relevance, quality, and structure of a website. Understanding the concept of crawling is vital for website owners and SEO practitioners seeking to enhance their online presence and improve their site’s performance in organic search.
How do search engine crawlers work?
Search engine crawlers, also known as bots or spiders, play a vital role in the functioning of SEO by systematically scanning websites to gather information for search engine indexing. These automated programs navigate the vast expanse of the internet by following links from one web page to another, collecting data on content, structure, and relevance along the way. By understanding how search engine crawlers work, website owners can optimise their sites for efficient crawling and indexing, ultimately improving their visibility and ranking on search engine results pages.
Why is crawling important for SEO?
Crawling is a vital component of SEO as it allows search engines to discover, index, and rank web pages based on their relevance and quality. By crawling websites, search engine bots can gather information about the content, structure, and links within a site, enabling them to determine its relevance to users’ search queries. A well-crawled website increases the likelihood of its pages appearing in search results, driving organic traffic and improving online visibility. Without effective crawling, search engines may struggle to index a website’s content accurately, leading to lower rankings and reduced visibility in search engine results pages. In essence, crawling is essential for SEO as it lays the foundation for a website’s presence in the digital landscape and influences its performance in organic search results.
What are some common issues related to crawling in SEO?
In the realm of SEO, common issues related to crawling often revolve around accessibility and indexability of web pages. One prevalent issue is crawl errors, which can occur due to broken links, server connectivity problems, or improper redirections. Additionally, issues with robots.txt files or meta robots tags can inadvertently block search engine crawlers from accessing important content on a website. Another common challenge is duplicate content, which can confuse search engines and dilute the visibility of a website in search results. Furthermore, slow page loading speed and complex website structures can hinder efficient crawling and indexing by search engine bots. Addressing these common crawling issues through regular monitoring, error resolution, and strategic optimization is essential for enhancing a website’s overall SEO performance.
How can I improve the crawlability of my website?
Improving the crawlability of your website is essential for enhancing its visibility and ranking on search engine results pages. To achieve this, there are several key steps you can take. Firstly, ensure that your website has a clear and logical site structure with well-organized navigation to help search engine crawlers easily navigate through your content. Secondly, focus on creating a sitemap.xml file that lists all the important pages on your site, making it easier for search engines to discover and index your content. Additionally, regularly monitor and fix any crawl errors, broken links, or duplicate content issues that may hinder the crawling process. By implementing these strategies and continuously optimising your website for crawlability, you can improve its chances of being effectively indexed and ranked by search engines.
What is the difference between crawling and indexing?
In the realm of SEO, a common query revolves around the distinction between crawling and indexing. Crawling refers to the process where search engine bots systematically navigate through websites to discover and gather information about their content. On the other hand, indexing involves storing and organizing this collected data in a searchable database. In essence, crawling is akin to exploring a library to find books, while indexing is akin to cataloguing those books for easy retrieval. Understanding this difference is crucial for website owners aiming to enhance their online visibility and improve their rankings on search engine results pages.
Are there any tools available to help monitor website crawling activity?
Monitoring website crawling activity is essential for ensuring that search engines can effectively discover and index web pages. Fortunately, there are several tools available to assist in tracking and analysing crawling behaviour. Popular tools like Google Search Console provide valuable insights into how search engine bots interact with a website, highlighting crawl errors, indexing status, and other relevant data. Additionally, third-party tools such as Screaming Frog SEO Spider and DeepCrawl offer comprehensive crawling reports, allowing website owners to monitor crawl frequency, identify issues hindering indexing, and optimise their site’s overall crawlability. By leveraging these tools, webmasters can gain valuable insights into their website’s performance in search engine crawls and take proactive steps to improve their SEO efforts.
What are some best practices for optimising a website’s crawl budget?
When it comes to optimizing a website’s crawl budget, several best practices can help ensure that search engine crawlers efficiently discover and index important web pages. Firstly, prioritizing high-quality content and eliminating duplicate or low-value pages can prevent crawlers from wasting resources on irrelevant content. Additionally, setting up proper URL structures, implementing efficient internal linking, and using XML sitemaps can guide crawlers to essential pages and improve crawl efficiency. Regularly monitoring crawl errors, fixing broken links, and managing redirects can also help maintain a healthy crawl budget. By following these best practices, website owners can enhance their site’s crawlability and increase the chances of their content being indexed and ranked effectively in search engine results.